Intelligent Regulatory Compliance

Building regulations are generally hard to work with. The Intelligent Regulatory Compliance (I-ReC) project aims to develop computational tools that improve the usability of regulatory documents. An example of a simple issue is retrieving relevant documents, which is complicated because of the specific language used in regulations, as well as licensing restrictions. A more complex issue is Compliance Checking, e.g., checking whether a building or building product complies with the relevant regulations. In the I-ReC project I worked towards decomposing and resolving both of these problems.
>
The I-ReC project was a collaboration between
Heriot-Watt University (HWU),
Northumbria University (NUU) and
Building Research Establishment (BRE). It was funded by NUU, as well as by BRE under the
the
Construction Innovation Hub. The project was part of research towards an online
compliance tool as part of the UK government's
'Transforming Construction Challenge'
>
📃 Journal article on envisioned strategy towards ACC and work in this direction (Advanced Engineering Informatics, 2024)
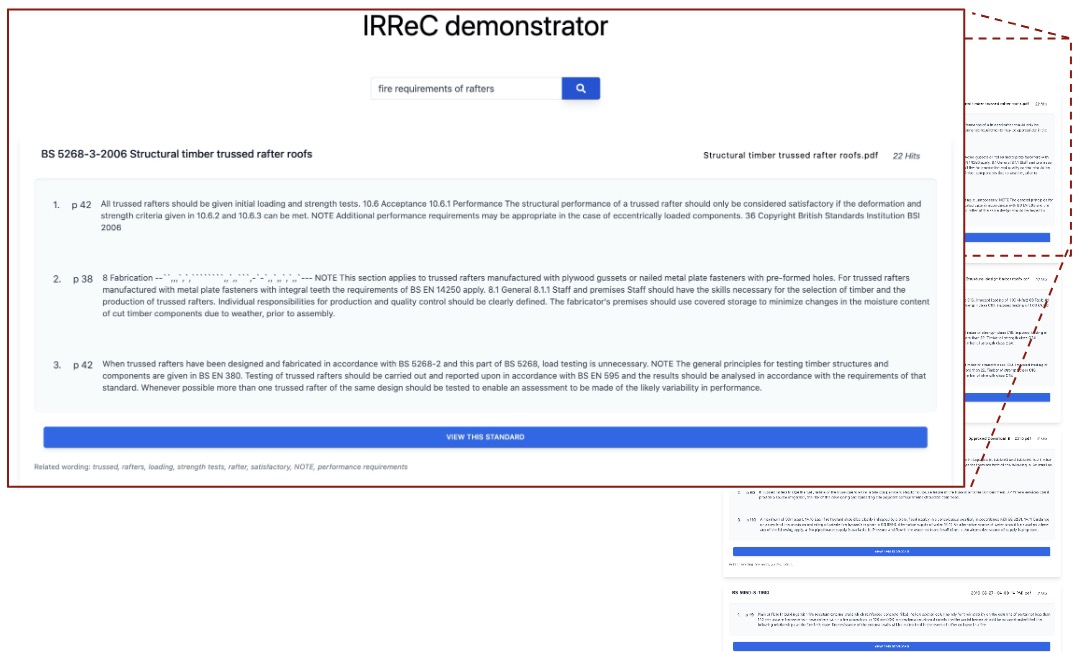
Designed and developed a passage retrieval system over building regulations in PDF format. This proof-of-concept systems relies on work described below
(text-to-KG and SPaR.txt). Evaluation relies on a carefully crafted dataset, based on thorough end-user interviews that were conducted in collaboration with
BIM academy.
The system achieves 65 Mean Average Precision @ top-3 results and allowed exploring various approaches to query and document expansion.
>
📃 Paper (EG-ICE 2023)
>
💻 Code and data (GitHub)
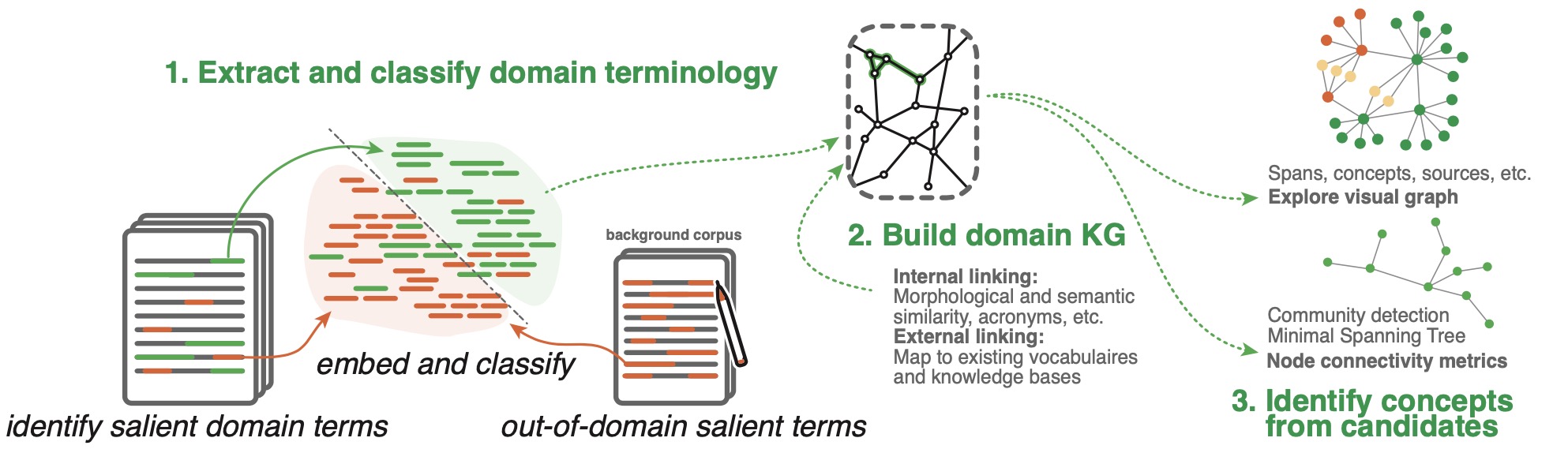
Despite decades of work towards Automated Compliance Checking (ACC), there are currently
no end-to-end solutions. And there may well never be an end-to-end solution for many of the
rules captured in building regulations. Instead, we argue that research towards Compliance
Checking should focus on feasible tools that add value now. One step in this direction is
the collection of a domain lexicon. To this end, we developed a text-to-KG (Knowledge Graph)
tool. Preliminary results show that the tool can reduce the time spent on manually collecting
a lexicon by more than 90%.
>
📃 Paper on the difficulty of ACC (LDAC 2023)
>
📃 Paper text-to-KG (LDAC 2023)
>
📹 Presentations (Plenary session 3 recording, last 2)
>
💻 Code and data text-to-KG (GitHub)
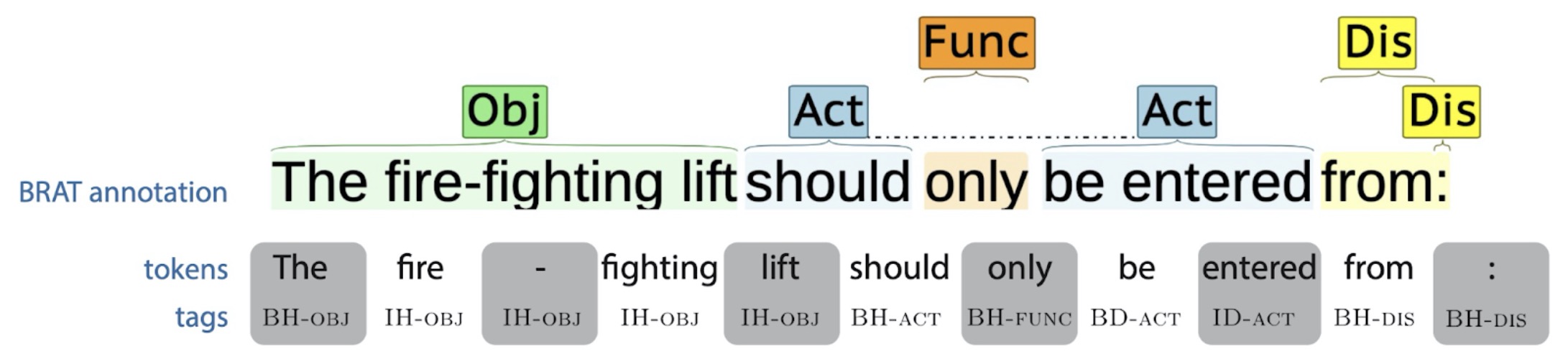
Short 3-month project to investigate the use of Natural Language Processing over building
regulations. This study focuses on discovering Multi-Word Expressions in building regulations
to improve and enable work on downstream tasks. Specifically, we introduce a shallow parsing
task for which training data is relatively cheap to create. Based on a small domain-specific
dataset of 200 sentences, we train a sequence tagger that achieves 79,93 F1-score
on the test set. We then show through manual evaluation that the model identifies most
(89,84) defined terms in a set of building regulation documents, and that both
contiguous and discontiguous Multi-Word Expressions (MWE) are discovered
with reasonable accuracy (70,3).
>
📃 Paper (NLLP @ EMNLP 2021)
>
📹 Presentation (Youtube)
>
💻 Code and data (GitHub)